
그룹딜레이(GD)의 중요성과 FR의 완결성
 SunRise
SunRise
완성된 글은 아니지만 회원님과 대화가 오간다면 괜찮지 않을까 해서 올려봅니다.
본문은 저의 청취 경험에 전적으로 기반한 내용이라 틀린 내용이 있을 수 있습니다.

ASR은 헤드폰에서 그룹딜레이(이하 GD) 측정치를 올립니다.
어떤 것이 이상적인 GD일까요? 그리고 FR, THD, GD의 관계는 무엇일까요?
저는 그에 대해 정리하면서 회원님들과 답을 찾고자 합니다.
먼저 스피커에서 답을 찾아봅니다.
인터넷을 검색하던 중 좋은 글을 찾아 쉽게 편집보강하였습니다.
(출처 : https://gall.dcinside.com/mgallery/board/view/?id=speakers&no=51768)
스피커는 전기 신호를 입력 받고 음파를 출력하는 시스템이며,
그 중에 선형적이고 시간에 무관한 것이 LTI 시스템입니다. 스피커도 LTI 시스템입니다.
LTI 시스템의 임펄스 응답을 알게 되면 입력신호로 출력신호를 계산해낼 수 있습니다.
즉, 특정 LTI 시스템의 임펄스 응답을 알고 있다면 그 LTI시스템의 모든 정보를 알수 있습니다.
스피커의 임펄스 응답을 알고 있다면 스피커의 주파수측정치(FR)를 도출할 수 있습니다.
하지만 임펄스 응답은 주파수가 아닌 시간 영역에서 정의된 전달 함수입니다.
그래서 시간 영역을 주파수의 영역으로 바꿔줘야 합니다.

그것이 푸리에 변환입니다.
그런데 푸리에 변환을 하면 실수였던 값들이 복소수로 바뀝니다.
실수는 ‘길이’, 복소수는 ‘길이’+‘방향’에 대한 정보를 가지고 있습니다.
이때 ‘길이’는 주파수응답 그래프, ‘방향’은 위상응답 그래프로 그려집니다.

이상적인 스피커는 모든 주파수의 소리가 동시에 재생됩니다.
하지만 신호처리를 하다 보면 시간지연이 생깁니다.
만약 모든 주파수에 대해서 1ms의 지연시간이 생긴다면 다음과 같은 그래프가 그려집니다.

그건 파동의 딜레이가 시간단위가 아니라 각도 단위(Y축; Degrees)로 표현되어 지그재그로 나오기 때문입니다.

그렇기에 두 파동 사이에 같은 시간차이가 나더라도 주파수에 따라서 위상차이가 발생합니다.
문제는 우리가 해석하기가 어렵다는 점입니다.
위상응답 그래프에서 Y축을 시간단위로 바꿉니다. 그것이 그룹 딜레이(GD)입니다.
GD를 보면 모든 주파수의 소리가 동시에 나오는지 확인할 수 있습니다.


노이만 KH420 GD와 FR입니다.
0Hz까지 소리가 나는 스피커는 없으므로 극저역 대역폭 한계를 가집니다.
로우컷 필터와 같은 결과가 나타나는데 거기서 위상지연이 발생합니다.
Q. GD특성이 좋지 않다면?
악기에서 하나의 음을 연주할 때는 하나의 주파수만 나오지 않습니다.
근음이 되는 주파수의 배음들이 같이 나오기 때문에 440Hz의 음을 연주하면 880Hz, 1320Hz 등의 주파수가 동시에 나옵니다.
그렇기에 주파수마다 재생되는 타이밍이 다르다면 원음이 훼손됩니다.
음의 해상도와 관련이 있다고 할 수 있습니다.
이상은 스피커에서 GD를 보는 방법이었습니다.
이어컵 내부에 자체적인 공간을 가진 헤드폰에서는 어떨까요?
아쉽게도 ASR에서도 측정만 하고 특별한 내용이 없어 보입니다.
https://www.audiosciencereview.com/forum/index.php?threads/on-group-delay-and-spatial-effects.22430/
그나마 Presently42 유저가 정리한 내용이 있습니다만 별다른 논의가 없습니다.
그래서 제 개인적인 청취 경험을 바탕으로 설명해보겠습니다.
여러 GD 중 소니의 모니터링 헤드폰인 MDR-7506이 설명하기 쉬울 것 같아 들고옵니다.
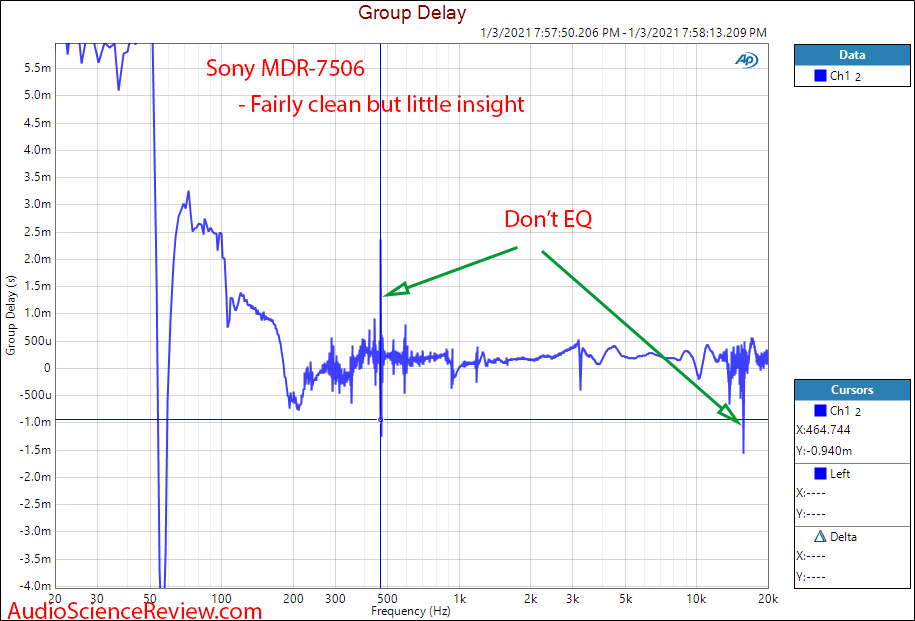
전반적으로 이상적인 응답입니다.
들어보면 드라이버에서 나온 소리가 귀로 온전히 들어간다는 인상입니다.
이어컵 내부의 공간이 매우 협소하고 장력이 제법 있어 귀에 딱 붙기 때문입니다.
그래서 공간감이 없는 이어폰 소리가 납니다.
55Hz, 200Hz가 튀는데 THD를 먼저 살펴보겠습니다. FR은 그 다음에 보겠습니다.

음.. 엉망이군요. 줌아웃 해봅니다.

극저역 THD 수치가 좋은 편은 아닙니다.
ASR은 94가 아닌 104, 114 dBSPL까지 측정하는 점 참고 바랍니다.
55Hz, 200Hz의 피크가 역시 THD에서도 관찰됩니다.
FR도 나타날까요?

정확히 해당 위치에서 딥이 생깁니다.
제가 그래서 예전부터 RAW가 딥피크 없이 선형적으로 나오는 것이 가장 좋다고 말한 겁니다.
애초에 임펄스에서 파생된 그래프라 FR, GD, THD 모두 연관을 가질 수밖에 없습니다.
그래서 FR이 정확하게 같으면 소리가 같다고 예전부터 주장해왔습니다.
웨이블릿 사장님도 정모 때 물어보니 같은 의견이시고요.
제법 깔끔한 GD 특성을 보이는 필립스 피델리오 X2HR 측정치를 들고오겠습니다.
GD, THD, FR 순서입니다.



7506과 달리 1~5kHz에 수많은 반사음의 영향이 보입니다.
다른 헤드폰도 정확하게 해당 영역에서 나타납니다.
이는 내부 공간이 거대한 제품일 수록 정비례하는 경향을 보입니다.(아래 사진 참고)
청감적으로는 불필요한 음들이 난반사되어 흩뿌려집니다.
좋게 말하면 공간감, 중립적으로 말하면 반사음, 나쁘게 말하면 잡소리입니다.
점점 이어컵 내부 공간이 거대해지는 것으로 사이즈를 올립니다.




HEDD는 좀 심각하네요. FR을 봅시다.
400~6000Hz까지 정돈되지 못 한 모습을 보여줍니다.

정확하게 해당 부분에 영향이 나타납니다.
지금까지 FR로 이 부분까지 설명한 사람을 보지 못하여 제가 직접 이 글을 올립니다.
흔히 참고하시는 1/3 스무딩 FR은 토널밸런스밖에 못 봅니다. 그리고 GD, THD특성 전부 제거됩니다.
그렇다면 어느 GD 특성이 적절할까요?
답은 없습니다. 경험적으로 적어보겠습니다.
저는 HD800s의 정위와 공간감이 현재 시판된 헤드폰 중에서 이상적이라 느낍니다.
찾아보니 아래와 같습니다.
그리고 현재까지 제 지식수준에서 설명하기 어려운 부분까지 솔직하게 밝힙니다.

1~5kHz까지 적절한 어지러움이 보입니다.
55Hz, 70Hz, 9kHz 이상한 부분 잘 기억해두세요.

THD 지극히 이상적입니다. 위에서 말한 3부분 멀쩡합니다.

55Hz, 70Hz, 9kHz에서 문제점이 정확히 나타납니다. 하지만 그렇게까지 심각하지 않습니다.
다만 5.5kHz 피크는 전례없던 것이라 저도 해석이 어렵습니다.
여기서 적절한 비교군을 들고옵니다. 호불호가 거의 없는 포칼입니다.
오픈형과 밀폐형을 비교하겠습니다.

오픈형인 포칼 유토피아
저역도 부드럽게 떨어지고, 1~5kHz 공간감을 제외하면 완벽에 가깝습니다.

그리고 밀폐형인 포칼 셀레스티
역시 괜찮은 편입니다만 60Hz, 2.1kHz를 기억하세요.

아까와 마찬가지로 GD 60Hz, 2.1kHz 딥과 THD와 유의미한 상관관계를 찾을 수 없습니다.
제가 그래서 GD가 중요하다고 하는 겁니다.
현재까지 헤드폰에서 GD 살피는 사람은 한명도 못 봤습니다.
측정하는 곳도 ASR말고 없고요.

FR에서는 GD영향이 그대로 나타납니다. 60Hz, 2.1kHz 잘 보이시죠?
다만 해당 부분의 딥이 무조건 나쁘다고 볼 수는 없습니다.
현재까지는 원음 전달에 대해서 GD의 중요성을 말씀드린 것이지 인지음향과는 약간 다릅니다.

제가 즐겨 듣는 AKG K812입니다.
분명 고음부분에 강조된 부분(피크)이 있으나 앞뒤의 딥 덕분에 공격성이 상쇄 됩니다.
글이 자꾸만 길어지는데 좋은 밀폐형 헤드폰 GD 예시를 올리면서 마무리합니다.
(오픈형 헤드폰 GD 기준 : HD800s, 유토피아)
원음 전달 면에서는 제어가 잘 된 밀폐형이 가장 이상적입니다.
리스트를 쭉 보시면 아시겠지만 대부분 명작이라 칭송받는 제품입니다.





B&W 헤드폰 들어보면 토널밸런스가 별로였지 품질은 항상 뛰어났는데 특성 좋습니다.


DCA 스텔스가 가장 이상적이나 평판형 헤드폰이 전반적으로 자글거립니다.
자글거림 없이 깔끔한(편인) 노이만도 올려봅니다.

2.5kHz 부근은 하우징 공진으로 인한 상쇄효과입니다.
인지음향적으로는 분리도 향상과 공간감 형성입니다. 의도하였는지는 모르겠습니다.
KH420을 보면 측정을 못 할 회사는 아닌데 말이죠.
그외에는 상당히 깔끔한 모습니다.
4줄 요약
-그룹딜레이(GD)로 해상력&공간감 판단 가능합니다.
-FR을 올바르게 해석한다면 THD, GD 정보를 얻을 수 있습니다.
(FR이 같다는 것은 토널밸런스 그 이상의 의미를 지닙니다. FR이 같다면 오직 똑같은 헤드폰 뿐입니다)
-헤드폰의 구조 특성상 공간감이 좋지 않을수록 원음 전달력이 우수하다고 할 수 있습니다.
-오픈형 헤드폰 GD는 HD800s&유토피아, 밀폐형 헤드폰 GD는 스텔스&셀레스티&NDH20 예쁩니다.
한계
-EQ시 GD 변화 알수없음
-GD, FR과 관계 없는 THD의 원인이 불명확함(하우징 설계 문제로 추정)
-오픈형 헤드폰에서 이상적인 GD 응답을 명확히 제시하지 못 함
-정전형 헤드폰 분석 누락
-고수의 댓글을 감당할 자신이 없음
혹시나 틀린 점이 있다면 살살 부탁드립니다.
_끝
SunRise
 샥샥거미님 포함 9명이 추천
샥샥거미님 포함 9명이 추천

댓글 49
댓글 쓰기

fr측정시 스윕 사인파로 측정한다는 한계는 있지않을까요
이를태면 같은걸 측정하면 같은 fr이 나오지만
같은 fr이라고해서 소리가 같지는 않을것 같습니다.
이를태면 잔향이나 다이나믹스같은것들이요
잔향이라 함은 결국 하우징의 설계에 크게 좌우되는데, 이어컵 내부 반사까지 모의한다면 같은 헤드폰이 아닐까요?
FR에 GD특성이 반영되니 아무리 HD600을 EQ한다고 해서 HEDD와 같은 FR을 만드는 것은 불가능합니다.
이어폰은 아마 다를 겁니다.
https://seeko.kr/bbs/board.php?bo_table=forum_etc2_1&wr_id=978471
여기를 참고하시는게 더 빠를 것 같습니다.
같은 fr이어도 소리가 다를 수 있다는건 결국 다른소리여도 fr이 같게 나올수도 있는 가능성을 열어두는것인데
소리가 다르다면 fr이 다르게나온다가 전제로 깔리는거군요
일단 사람이 구별할수 없으면 같다고 보는지, 사람이 구별할 수 없더라도 측정상 다르면 다른것인지도 기준을 두어야 할 듯합니다.
저는 fr이 같다고해서 같다고 볼 수없는게 측정방식의 한계, 즉 소리의 다양한 요소중 일부만을 측정하고있고,
그 방식이 사인 스윕파인점에서 한계가 있을 거라고봅니다.
가령 사인 스윕파로 측정하는 특정 짧은 구간의 밸런스가 같더라도 CSD 측정처럼 시간축을 포함하면 실제론 다른 소리일 수도 있는 식으로요
CSD도 FR에서 특성이 나타나는 걸로 알고 있습니다.
https://gall.dcinside.com/board/view/?id=earphone&no=1943529
웨이블릿 사장님이 쓴 내용인데, CSD는 공진의 영향을 직접적으로 받으며 해당 공진은 FR에서도 나올 테니까요. 아래 헤스키비 님이 첨부하신 URL에 잘 설명되어 있습니다.
결국 바로 앞 댓글의
"일단 사람이 구별할수 없으면 같다고 보는지, 사람이 구별할 수 없더라도 측정상 다르면 다른것인지도 기준을 두어야 할 듯합니다."
여기로 귀결됩니다.
사람이 구별할 수 없다면 같은 소리다 라고 본다면, 사실 +-0.1db 이내의 fr차이는 같은소리다
라는 식의 논리도 가능해집니다.
거의 같은 fr에서의 csd차이보다 fr자체가 다른경우 소리차이가 크게 느껴지겠죠
그러나 그게 같은소리라고 할 수는 없지않느냐가 애초에 하려던 이야기입니다.
특히 특정 고음대역대에서의 피크 등 보다 극저음이나 저음대역대에서의 잔향차이는 상당히 체감되지않을까 싶습니다.
물론 현실적으로 저도 fr이 어느정도 "유사"하기만해도 소리가 "거의" 비슷하게 느껴진다고 생각하긴합니다. 심지어 약간의 fr차이는 잘 느끼기 어려운것도 맞지요 그러나 그게 같은소리라고 하진 않는달까요
자고 일어나면 어떤 댓글들이 달릴지 생각만해도 무시무시하네요.
'음향'은 알면 알수록 머리가 아파집니다...
이헤폰에서는 직접음이 대부분이고 반사음들은 너무나도 짧고 빠르게 치고들어와서 직접음과 반사음을 구분하지못하고 합쳐서 인식할거라고 생각했는데 그렇지 않은가보네요
섶퍼나 스피커도 포트형보다 밀폐형이 GD가 더 깔끔하게 나오는데 이헤폰도 마찬가지군요
이헤폰에서의 공간감하면 정전형 스탁스도 빼놓을수없는데 GD가 어떻게 나올지 참 궁금하네요
평판형이 자글자글한 이유는 DD 드라이버보다 전체적으로 더 균일하게 소리가 방사되서 반사음이 더 발생하기 떄문일까요? ㅡ 스피커 지향성처럼 ?
그럼 정전형도 평판형처럼 GD가 자글자글 할 확률이 높다는것이고??
하만에서 타겟 연구할 때 스탁스에 EQ 넣어서 선호도 조사했던 걸로 기억합니다.
스탁스 RAW FR보면 상당히 자글자글 했던 것 같은데 아마 말씀하신 내용에 해당하는 것 같습니다.
저 역시 절대적인 드라이버의 크기가 관건이라 생각합니다.
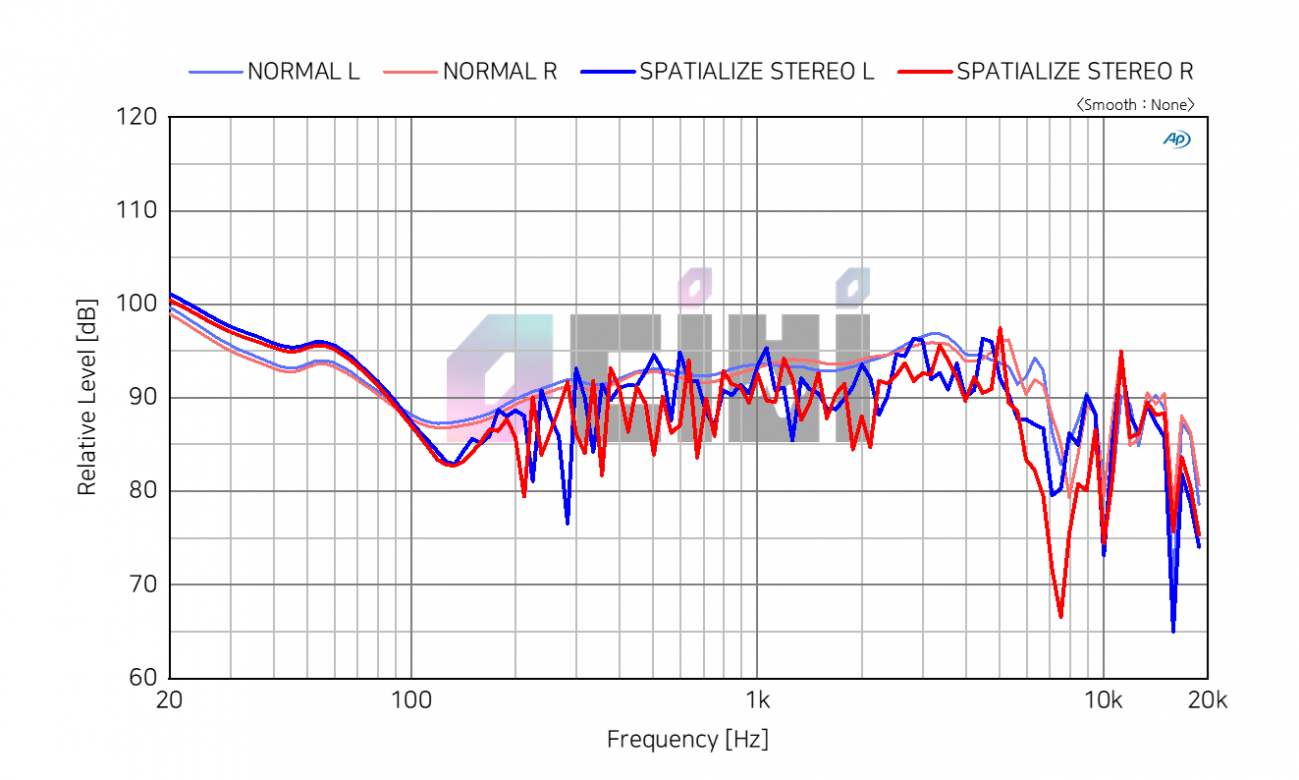
에어팟 맥스는 자글자글하게 인위적으로 만들어서 공간음향을 모사하였으니, 자글자글하다고 해서 무조건 나쁜 것은 아니라고 봅니다. 다만 이때부터는 반드시 청취평가가 수반되어야해서 측정치만 보고 판단하는 것은 밀폐형에 국한되는 듯 하네요.
해봐! 해보라고!!!! -ㅅ-;;;;
이미 개발은 하고있겠쥬? ㅎㅎ

그런데 평판자력형과 정전형은 음파의 지향성이 dd보다 뚜렷합니다
즉 지향각이 좁습니다
다이어프램이 오목하거나 볼록하지 않고 더 넓으니까요
그렇다면 일단 주변부에 둘러쳐진 패드 표면재질의 영향은 덜할 것입니다
덜 퍼질테니까요
그리고 그 대신에 헤드폰을 썼을 때 패드 내부에 들어가는 귓바퀴와의 맞반사의 영향이 아주 커지겠지요

음향 공학 쪽은 전문 분야가 아니라서 일단 판단을 유보하겠습니다.. orz
(좀 삐딱하게 보면 인과 관계 없이 데이터 끼워 맞추기로 판단할 가능성도 존재해서..)
일단 무식하게 구글 검색해서 나온 내용 중 비스무리한 내용들 걸어 봅니다.
https://www.head-fi.org/threads/group-delay-vs-fr-how-important.926373/
- 헤드파이 쪽 스레드입니다.
https://www.rtings.com/headphones/tests/sound-quality/imaging
- RTINGS 측정치 중에서도 일부는 (가중치 적용된) 그룹 딜레이 내용이 보이고 그걸 해설한 내용입니다.
안타깝게도 헤드파이 스레드에서도 역시 별다른 논의가 없습니다.
다만 로저스의 그룹딜레이 설명을 건졌네요.
로저스의 말에 따르면 GD 특성이 나쁠수록 사운드 스테이지를 잃어버린다고 합니다.
듣기에 좋을수 있어도 해당 악기의 위치 파악이 불가능해집니다. 소위 정위감이 (더 나아가 해상력)이 불명확해 집니다.
RTINGS는 날 잡고 ASR과 비교분석해야할 것 같습니다.
사실 THD도 94dBSPL에서 1%이하라면 우수하다고 뭉뚱그려 말할 수 있습니다. 특히 이어폰은 대부분 THD특성이 매우 우수해서 우열을 가리기가 쉽지 않습니다. 하지만 젠하이저의 낮은 왜율 사랑의 결과인 XWB를 들어보면 해당 부분이 가청되는 가에 따른 판단은 개인마다 다르지 않을까 싶습니다.
알팅스의 그룹딜레이는 세로축이 너무나도 크게 잡혀있어서 해당 GD만으로 오픈형인지 밀폐형인지 쉽게 판단하기가 어려울 정도로 해상도가 낮습니다. 서두에서 밝혔듯 청감적인 경험이 없었다면 해당 글을 작성조차 할 수 없었을 거예요.
예시가 있을까요? 오픈형인데 밀폐형과 같은 GD가 나온다거나 밀폐형인데 오픈형과 같은 GD가 나올 정도의 오차가 있다면 본문을 갈아엎어야 합니다.
imd도 참 공개되지 않는 정보인데 파면 팔수록 계속 나오네요.
다만 ASR에서 참고할 점은 다음과 같다고 생각합니다.
-1~5kHz에서 발생되는 지저분함은 오픈형의 개방감과 관계합니다. 저는 이 부분이 가장 중요하다고 봐요. 지금까지는 어떠한 측정치로도 직관적으로 확인할 수 없었으니까요.
-100Hz아래에서 GD가 완만하게 떨어지는 것이 좋으나 X2HR보다 셀레스티의 극저역 만족도가 높으므로 무조건적인 상관관계는 희미하다고 생각합니다.
-노이만에서 발생하는 2.4k 부분은 THD, FR과 더불어 GD에서도 보이지만 해당 부분은 오히려 FR로 인한 지각효과로 보이며 GD에서만 튀는 부분이 가청되는지는 연구가 필요합니다.
평판형제품이나 패드 내 공간이 크고 넓은 제품들에서의 공진특성은 csd같은 측정으로 어느정도 나타나는데, 헤드폰의 경우 잔향음이 매우 짧은편이기 때문에 보통은 주파수응답특성의 변형 정도로 지각됩니다. 이어패드 직경이 과도하게 큰 제품들 고음역대가 쭈글쭈글하게 측정되는건 이것 때문이라 보셔도 됩니다.
fr이랑 타겟 정합도만 보여주고 땡 하는게 제품 팔아먹기 좋기때문에 딱 그정도만 공개가 되는데, 저는 지금 시점에서 고음질을 논하려면 그 외 특성의 공개도 같이 이루어져야한다고 생각합니다. 깔 부분이 없도록 측정하려면 측정장비에 투입되는 비용이 과도하게 커지기 때문에 이렇게까지는 어렵겠습니다만, 이어폰/헤드폰/스피커 제조업체들에서는 다들 측정해서 db를 가지고 있을거에요.
기존 공개된 스펙, 측정치에서 제가 중요하게 보는 부분은 제품의 THD, 다이나믹 레인지, 위상응답(그룹딜레이 포함), 주파수응답특성, 스피커의 경우에는 스피노라마 데이터. 이정도 확인합니다. imd쪽은 thd좋게 나오는 경우 보통은 문제가 잘 없더라고요. 0.1미만으로 내려가야 고급기 딱지 달 수 있다고 생각해요.
오히려 이너피델리티의 아이솔레이션 측정치와 비슷한 역할로 전이되었다고 봐야겠네요.
사실 리니어한 RAW FR만 있어도 거의 충분하고, 추가로 본다면 THD 특성 포함해서 2가지만 보더라도 거의 완벽하다고 생각합니다. ASR처럼 94 104 114로 쭉 올려버리니 체급이 쉽게 구분되어서 괜찮은 방법으로 봅니다.


잘 읽고 갑니다.

흥미로운 주제네요. 이래저래 찾아보고 이야기해보고 싶은 부분이긴 합니다만.. 수능을 앞두고 있는 관계로 나중에 자세히 좀 생각해봐야겠습니다.
https://www.linkedin.com/pulse/csd-cumulative-spectral-decay-really-important-jason-dai
요 글도 한번 참고해보시면 좋을 것 같네요.
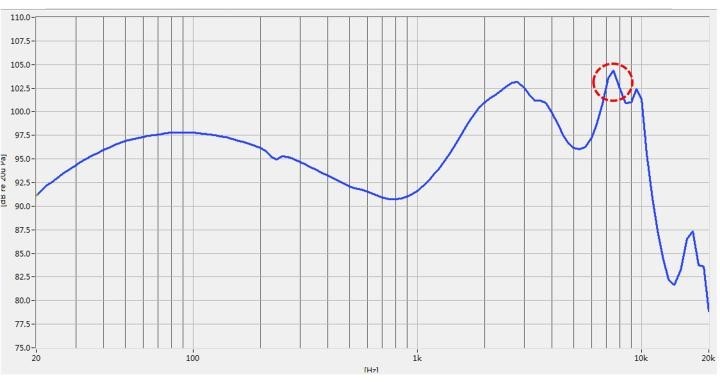
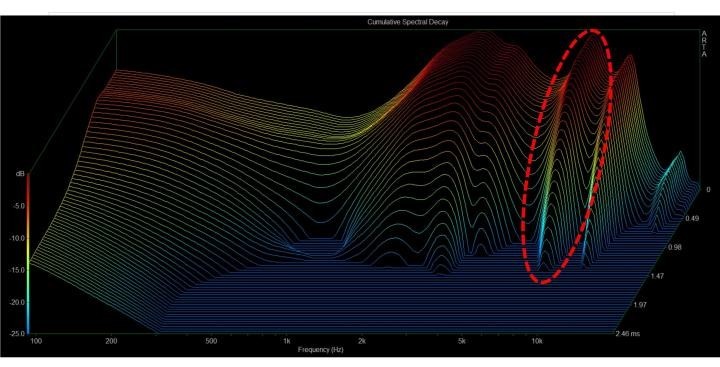
좋은 내용입니다.
Overall, about CSD, the truth is:
1. Solve frequency issue can solve CSD issue in most cases because of minimum-phase-system and Hilbert transform.
2. At least, what we hear is peak of frequency response curve, not “ringing” of CSD above 200Hz.
3. Low Q resonance is more sensitive to expose some “time domain issue
2. At least, what we hear is peak of frequency response curve, not “ringing” of CSD above 200Hz.
생각해보니 고음에서의 잔향차이는 크게 의식해본적이 없는거같네요
1. 현실의 스피커/헤드폰/이어폰은 결코 LTI 시스템이 아닙니다.
디씨스갤 게시물에 링크된 PDF에서도 아래와 같이 언급하고 있습니다.
(안 읽어도 무방한 부분이라는 원 인용자의 커멘트는 납득하기 어렵군요)
"The restrictions required by an LTI system are severe, so severe in fact that no real physical system meets them." (Douglas 2019: 47)
>> LTI 시스템에 요구되는 제한사항은 너무나도 엄격해서, 그 어떤 현실의 물리적인 시스템도 만족시킬 수 없을 정도이다.
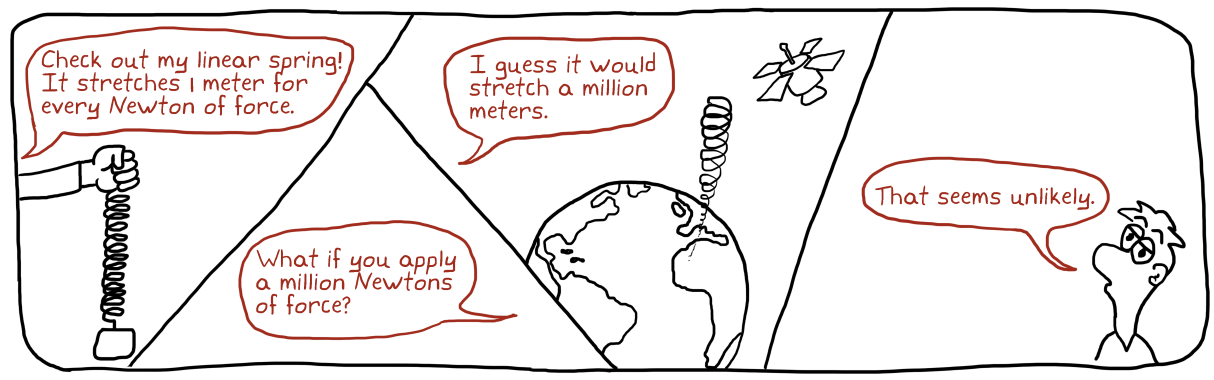
"내 선형 용수철을 보라구! 1뉴턴 힘당 1미터씩 늘어나!"
"백만 뉴턴의 힘을 적용하면 어떻게 되지?"
"백만 미터 늘어날걸."
"그럴리가..."
cf) 96dB 다이나믹 레인지(예: CD음원)에 해당하는 에너지량의 차이는 약 40억배입니다. 현실적 사물이 이 범위에서 선형적으로 동작한다는건 그야말로 "unlikely"하지요.
"임펄스응답IR"과 "주파수FR+위상응답GD"을 상호 필요충분적으로 푸리에 변환할 수 있다는건 LTI 시스템이라는 수학적 모델의 특성입니다. 현실의 전기-음향 변환기의 특성이 결코 아닙니다.
이 모델을 써서 "완전한 LTI 시스템이지만 FR이 평탄하지 않은 가상의 불완전한 변환기"의 불완전성을 수학적으로 완전하게 설명할 수 있습니다. 이 경우 "동일한 FR + 동일한 GD = 동일한 임펄스 = 동일한 변환기"라는 명제는 참입니다.
그러나, "LTI 시스템을 불완전하게 모사하면서 FR이 평탄하지 않은 현실의 불완전한 변환기"의 불완전성은 수학적 LTI 모델로는 완전하게 설명할 수 없습니다. "동일한 FR + 동일한 GD = 동일한 임펄스 = 동일한 변환기"라는 명제가 증명될 수 없는 겁니다.
(어느 정도의 "유사성"이 존재하는건 확실한데, 이 바닥에서 "유사성"만으로 만족하자면 에디슨 축음기와 초하이엔드 오디오 시스템도 대충 서로 유사하다고 퉁칠 수 있게 되어 논의의 의미가 없어집니다.)
...
그럼에도 불구하고 일단은 특정 "범위region" 안에서 동작하는 전기-음향 변환기(스피커, 헤드폰, 이어폰)을 LTI 시스템으로 간주할 수 있다고 가정하고 다음 문제로 넘어갑니다.
"Even though no real system is LTI there are, however, a wide range of real problems can be approximated very accurately with an LTI model. As long as your system behaves linearly over some region of operation, then you can treat it as LTI over the region." (ibid.)
>> "현실에 LTI 시스템이 존재하지 않는다고 하더라도, 광범위한 현실적 문제들이 LTI 모델로써 아주 정확하게 근사(近似)할 수 있다. 시스템이 일부 작동 범위에서 선형적으로 작동하는 한, 해당 범위에서 LTI로 취급할 수 있다."
이때 현실의 변환기가 수학적 LTI 모델을 흉내내며 작동할 수 있는 "범위region"는 최고주파수, 최저주파수, 최대변위, 노이즈플로어라는 4변의 "박스"로 제한됩니다.
2. 변환기 앞단에 붙는 필터(예: EQ)의 문제
"FR이 같다면 오직 똑같은 헤드폰 뿐입니다"라는 명제가 아주 위험한 명제인게, 이 "헤드폰"을 LTI 시스템에 준하는 변환기로 정의하는 범위가 어디서부터 어디까지인지 명확하지 않다는 겁니다.
만약,
"갑"이라는 변환기에 신호A를 입력했더니 A'라는 패턴의 FR이 나오고,
"을"이라는 변환기에도 같은 신호A를 입력했더니 똑같이 A'라는 패턴의 FR이 나왔다!
GD도 똑같다!
...라면 "갑"과 "을"은 사실상 어느 범위 안에서는 동일한 변환기라고 볼 수 있습니다.
"병"이라는 변환기에 똑같은 신호A를 넣었더니 전혀 다른 A+d가 출력되는 경우도 있을 겁니다.
이 변환기 전단에 A를 받아서 A-d를 출력하는 EQ필터(즉, "병"의 역함수)를 투입해서 최종적으로 "병"이 A를 출력하게 한다면, 과연 "EQ필터+병"으로 묶인 새로운 변환기를 "갑" 또는 "을"과 동일한 변환기라고 할 수 있을까요?
편차d는 음질 저하를 양적으로 표현하는 지표입니다. 그리고 "전기→음향" 에너지 변환에서 일어나는 이 편차d는 엔트로피 증가를 수반하는 비가역적 정보손실입니다. EQ필터가 만들어내는 -d라는 편차도 SNR 축소를 수반하는 비가역적 정보손실입니다.
EQ필터와 헤드폰이 각각 독자적인 완전한 LTI 시스템이라면, 이 두 LTI 시스템이 서로 역함수 관계일 때 이 둘을 직렬로 통과하면 원래 정보가 그대로 나올 거라고 수학적 추론을 할 수 있습니다만...
현실에서는 EQ필터도 헤드폰도 제한된 범위에서만 LTI 시스템을 흉내내며 작동하는 모사물에 불과하기 때문에, 두 불완전 LTI 시스템이 진짜 수학적 LTI 모델을 따라서 작동하는 범위는 편차d가 크면 클수록 좁아집니다. 노이즈플로어가 올라오고 최대 변위 제한이 내려오면서 파형 속의 미세한 정보들이 엔트로피 증가분으로 변환되어 흩어져버립니다. 톤밸런스만 비슷한 후진 소리가 되어버리는거지요.
3. 변환기 뒤에 따라오는 물리적 필터(예: 공간)의 문제
무향실(FF)에 놓인 스피커에서 빡!하고 발생한 최초 attack이 측정 마이크에 도달하고 뒤이어 sustain, releases, decay가 따라올 때, 시간축을 따라 변화하는 압력의 변화를 측정해서 임펄스응답IR을 얻고, 이것을 주파수응답FR + 위상응답GD로 푸리에 변환할 수 있으며, 이것으로 스피커의 모든 것을 알 수 있습니다.
이는 크로스오버 네트워크나 DSP로 위상을 크게 손대지 않은 평범한 유선 이어폰/헤드폰의 드라이버 혹은 싱글유닛 풀레인지 스피커는 GD응답이 다 고만고만하므로 FR만으로 모든 것을 다 설명할 수 있어야 한다는 이야기도 됩니다.
단, 여기에는 한 번 발생-측정을 거친 음파가 다시 측정기기로 반사되어 되돌아오지 말아야 한다는 조건이 붙습니다. 만약 decay가 진행되는 도중에 최초 attack이 공간에서 반사되서 다시 측정마이크로 돌아와버리면...? 결과적으로 FR이 똑같이 나오게끔 변환기 전단에 EQ를 걸었다고 하더라도 임펄스 응답이 크게 틀어져버립니다. 잔향의 유무 혹은 특정한 CSD패턴이 음질이 좋고 나쁨을 말해준다는게 아니라, 잔향 패턴의 차이로 인해서 FR이 음질을 완전히 반영한다는 가정 자체가 성립이 안 된다는 얘깁니다.
무향실(FF)에 놓인 두 스피커의 FR이 모든 축상에서 같다면 두 스피커는 사실상 똑같은 변환기입니다. GD가 아마도 거의 똑같을 거고, 그러면 IR도 똑같을 겁니다. 여기에 이의는 없습니다. 일부 축상에서만 똑같다고 하더라도, "그 축상 응답만 활용할거다"라는 (비현실적인) 조건을 붙인다면 사실상 똑같은 변환기로 취급할 수 있습니다.
그러나 서로 다른 공간에 놓인 서로 다른 스피커의 FR이 똑같다면 그건 우연에 불과합니다.
무향실에서 플랫한 스피커를 잔향실에 가져다 놓고 EQ로 플랫하게 맞춰도 소리가 다릅니다.
잔향실에서 주파수 응답이 울룩불룩한 스피커를 무향실에 가져다 놓고 EQ로 똑같이 울룩불룩한 FR을 모의해도 소리가 다릅니다.
헤드폰 또는 이어폰의 진동판을 레이저로 찍어서 FR이 같다면 똑같은 유닛입니다. GD가 아마도 거의 똑같을 거고, 그러면 IR도 똑같을 겁니다.
그런데 헤드폰/이어폰은 사람의 머리와 물리적으로 결합되면서 소리가 방사되는 공간을 같이 제공합니다.
"서로 다른 헤드폰/이어폰"은 "서로 다른 변환기 & 서로 다른 공간"이 결합된 패키지입니다.
"서로 다른 헤드폰/이어폰"의 FR이 똑같다면 그건 우연에 불과합니다.
물론 공간의 유사성이 스피커 환경에 비해서 큰 편이므로, FR로 모든걸 알 수 있는 확률이 좀 더 높기는 합니다.
::요약::
"FR + GD ⇄ IR"이 모든걸 말해준다는 "완결성"은 수학적으로 완전한 이상적인 LTI 시스템에서만 보장되며, 현실의 전기-음향 변환기는 선형적으로 동작하는 범위가 제한되어 있기에 완전한 LTI 시스템이 아닙니다.
현실의 불완전한 LTI 시스템이 선형적으로 동작하는 범위를 정의하지 않으면, 두 변환기의 "FR + GD ⇄ IR"이 일치한다고 하더라도, 그로부터 나오는 변환결과가 서로 얼마나 일치하게 될지는 알 수 없습니다.
FR이 똑같은 두 개의 완전한 LTI 시스템을 가정하더라도, IR이 다르다면 전혀 다른 소리가 나옵니다. LTI 시스템에 대해서 모든 정보를 알려주는 것은 FR이 아닌 IR(즉, FR + GD)이기 때문입니다.
참고문헌
Douglas, B. (2019). The Fundamentals of Control Theory.
* 디씨스피커갤 글에 링크된 바로 그 PDF입니다
https://gall.dcinside.com/mgallery/board/view/?id=speakers&no=51768
결국 남는 것은 GD가 청감적으로 미치는 영향(드라이버 각도로 인한 공간감, 내부 챔버의 용적, 드라이버의 크기 등)을 서두에서 밝혔듯 개인 경험과 결부시킨 것이 전부입니다.
궁금한 점이라면 미니멈페이즈에 가까운 이어폰은 LTI로 볼 수 있는지요?
네, 미니멈페이즈에 가까운 이어폰은 주어진 다이나믹 레인지와 주파수 레인지라는 범위 안에서 LTI로 볼 수 있다고 생각합니다.
몇 가지 조건이 충족된다면 이어폰으로 모든 소리를 모사할 수 있다고 생각합니다.
재생장비(이어폰)의 조건
1) 밀폐된 이도에서 발생하는 공진을 완전히 가청주파수 바깥으로 밀어낼만큼 깊이 삽입
2) 진동판이 가청영역 전부를 커버하는 다이나믹 레인지 이내에서 완벽하게 선형적으로 동작
3) 이어폰 진동판의 신호/변위 FR이 플랫
4) 0으로 수렴하는 그룹 딜레이
그런데 상식적으로, 귀 안으로 들어간 재생장비에다가 귀 바깥에서 녹음된 소스를 재생하면 안 됩니다. 해당 이어폰 사용자와 동일한 HRTF를 갖는 커스텀 더미헤드의 이도 속 동일한 위치에, 위 재생장비와 동일한 조건을 만족하는 초소형 마이크를 설치해서 소스를 수급해야만 합니다.
커스텀 더미헤드에 HD800s을 씌우고 녹음한 소스를 해당 기준을 모두 만족하는 이어폰에서 재생하면 HD800s를 쓰고 듣는 것과 똑같은 소리를 들을 수 있을 뿐만 아니라, HE-1이건 X9000이건 다 모의할 수 있고 자연음과 똑같은 경험을 하는 것도 가능할 거 같습니다. 물론 여기에 사용된 이어폰과 마이크의 다이나믹/주파수 "범위" 안에서요.
해당 조건을 만족하는 이어폰/마이크의 실존은 현재 기준으로 비현실적이지만, 언젠가는 기술적으로 가능해질지도 모릅니다. 진짜 문제는 소스를 수급하는데 커스텀 더미헤드가 필요하다는 겁니다. 도저히 대중매체 소비 용도로 쓸 수가 없지요.
귀 바깥에서 녹음한 소스에다가, 개별 청취자 귀를 고막 근처까지 라이다 스캔해서 얻은 HRTF의 역함수 EQ필터를 씌워서 동일한 효과를 볼 수 있을지도 모르겠습니다. 그나마 가장 실현 가능성이 높은 방법이긴 한데, 제 답글 2항에서 언급한 것처럼 LTI 동작 범위가 축소되는 음질 열화가 발생합니다.
그래도 만약 EQ필터, 마이크, 이어폰의 선형적 동작 범위가 가청 주파수/다이나믹 범위를 전부 덮고도 한참 남을만큼 뛰어나다면 완전한 원음 재생이 가능할 거라고 생각합니다.
감사합니다. 살살 적어주셔서 이해하기 수월했습니다.
고음량과 관계 없이 소리의 명료도는 이어폰이 헤드폰보다 우수하다고 느껴서 잘만 조작한다면 이상적인 제품이 나올 것 같은데, 선도적인 위치에 있는 애플이 잘 만들어줬으면 하는 바람입니다.
FR이 정확히 같으면 소리가 같다는 웨이블릿 사장님 말씀에 이제는 완전히 납득이 갑니다.











![[리뷰] 정전형 헤드폰 역사의 시작, SR-람다 프로(1982년)](/files/thumbnails/208/794/003/150x120.ratio.jpg?t=1714317204)




![[초두] EPZ G10 가성비의 정의](/files/thumbnails/937/781/003/150x120.ratio.jpg?t=1713876760)














![[시리즈] MTW를 사용해보자 : 비청(인트로 편)](/files/thumbnails/787/736/003/150x120.ratio.jpg?t=1712151605)
1. 현실의 스피커/헤드폰/이어폰은 결코 LTI 시스템이 아닙니다.
디씨스갤 게시물에 링크된 PDF에서도 아래와 같이 언급하고 있습니다.
(안 읽어도 무방한 부분이라는 원 인용자의 커멘트는 납득하기 어렵군요)
"The restrictions required by an LTI system are severe, so severe in fact that no real physical system meets them." (Douglas 2019: 47)
>> LTI 시스템에 요구되는 제한사항은 너무나도 엄격해서, 그 어떤 현실의 물리적인 시스템도 만족시킬 수 없을 정도이다.
"내 선형 용수철을 보라구! 1뉴턴 힘당 1미터씩 늘어나!"
"백만 뉴턴의 힘을 적용하면 어떻게 되지?"
"백만 미터 늘어날걸."
"그럴리가..."
cf) 96dB 다이나믹 레인지(예: CD음원)에 해당하는 에너지량의 차이는 약 40억배입니다. 현실적 사물이 이 범위에서 선형적으로 동작한다는건 그야말로 "unlikely"하지요.
"임펄스응답IR"과 "주파수FR+위상응답GD"을 상호 필요충분적으로 푸리에 변환할 수 있다는건 LTI 시스템이라는 수학적 모델의 특성입니다. 현실의 전기-음향 변환기의 특성이 결코 아닙니다.
이 모델을 써서 "완전한 LTI 시스템이지만 FR이 평탄하지 않은 가상의 불완전한 변환기"의 불완전성을 수학적으로 완전하게 설명할 수 있습니다. 이 경우 "동일한 FR + 동일한 GD = 동일한 임펄스 = 동일한 변환기"라는 명제는 참입니다.
그러나, "LTI 시스템을 불완전하게 모사하면서 FR이 평탄하지 않은 현실의 불완전한 변환기"의 불완전성은 수학적 LTI 모델로는 완전하게 설명할 수 없습니다. "동일한 FR + 동일한 GD = 동일한 임펄스 = 동일한 변환기"라는 명제가 증명될 수 없는 겁니다.
(어느 정도의 "유사성"이 존재하는건 확실한데, 이 바닥에서 "유사성"만으로 만족하자면 에디슨 축음기와 초하이엔드 오디오 시스템도 대충 서로 유사하다고 퉁칠 수 있게 되어 논의의 의미가 없어집니다.)
...
그럼에도 불구하고 일단은 특정 "범위region" 안에서 동작하는 전기-음향 변환기(스피커, 헤드폰, 이어폰)을 LTI 시스템으로 간주할 수 있다고 가정하고 다음 문제로 넘어갑니다.
"Even though no real system is LTI there are, however, a wide range of real problems can be approximated very accurately with an LTI model. As long as your system behaves linearly over some region of operation, then you can treat it as LTI over the region." (ibid.)
>> "현실에 LTI 시스템이 존재하지 않는다고 하더라도, 광범위한 현실적 문제들이 LTI 모델로써 아주 정확하게 근사(近似)할 수 있다. 시스템이 일부 작동 범위에서 선형적으로 작동하는 한, 해당 범위에서 LTI로 취급할 수 있다."
이때 현실의 변환기가 수학적 LTI 모델을 흉내내며 작동할 수 있는 "범위region"는 최고주파수, 최저주파수, 최대변위, 노이즈플로어라는 4변의 "박스"로 제한됩니다.
2. 변환기 앞단에 붙는 필터(예: EQ)의 문제
"FR이 같다면 오직 똑같은 헤드폰 뿐입니다"라는 명제가 아주 위험한 명제인게, 이 "헤드폰"을 LTI 시스템에 준하는 변환기로 정의하는 범위가 어디서부터 어디까지인지 명확하지 않다는 겁니다.
만약,
"갑"이라는 변환기에 신호A를 입력했더니 A'라는 패턴의 FR이 나오고,
"을"이라는 변환기에도 같은 신호A를 입력했더니 똑같이 A'라는 패턴의 FR이 나왔다!
GD도 똑같다!
...라면 "갑"과 "을"은 사실상 어느 범위 안에서는 동일한 변환기라고 볼 수 있습니다.
"병"이라는 변환기에 똑같은 신호A를 넣었더니 전혀 다른 A+d가 출력되는 경우도 있을 겁니다.
이 변환기 전단에 A를 받아서 A-d를 출력하는 EQ필터(즉, "병"의 역함수)를 투입해서 최종적으로 "병"이 A를 출력하게 한다면, 과연 "EQ필터+병"으로 묶인 새로운 변환기를 "갑" 또는 "을"과 동일한 변환기라고 할 수 있을까요?
편차d는 음질 저하를 양적으로 표현하는 지표입니다. 그리고 "전기→음향" 에너지 변환에서 일어나는 이 편차d는 엔트로피 증가를 수반하는 비가역적 정보손실입니다. EQ필터가 만들어내는 -d라는 편차도 SNR 축소를 수반하는 비가역적 정보손실입니다.
EQ필터와 헤드폰이 각각 독자적인 완전한 LTI 시스템이라면, 이 두 LTI 시스템이 서로 역함수 관계일 때 이 둘을 직렬로 통과하면 원래 정보가 그대로 나올 거라고 수학적 추론을 할 수 있습니다만...
현실에서는 EQ필터도 헤드폰도 제한된 범위에서만 LTI 시스템을 흉내내며 작동하는 모사물에 불과하기 때문에, 두 불완전 LTI 시스템이 진짜 수학적 LTI 모델을 따라서 작동하는 범위는 편차d가 크면 클수록 좁아집니다. 노이즈플로어가 올라오고 최대 변위 제한이 내려오면서 파형 속의 미세한 정보들이 엔트로피 증가분으로 변환되어 흩어져버립니다. 톤밸런스만 비슷한 후진 소리가 되어버리는거지요.
3. 변환기 뒤에 따라오는 물리적 필터(예: 공간)의 문제
무향실(FF)에 놓인 스피커에서 빡!하고 발생한 최초 attack이 측정 마이크에 도달하고 뒤이어 sustain, releases, decay가 따라올 때, 시간축을 따라 변화하는 압력의 변화를 측정해서 임펄스응답IR을 얻고, 이것을 주파수응답FR + 위상응답GD로 푸리에 변환할 수 있으며, 이것으로 스피커의 모든 것을 알 수 있습니다.
이는 크로스오버 네트워크나 DSP로 위상을 크게 손대지 않은 평범한 유선 이어폰/헤드폰의 드라이버 혹은 싱글유닛 풀레인지 스피커는 GD응답이 다 고만고만하므로 FR만으로 모든 것을 다 설명할 수 있어야 한다는 이야기도 됩니다.
단, 여기에는 한 번 발생-측정을 거친 음파가 다시 측정기기로 반사되어 되돌아오지 말아야 한다는 조건이 붙습니다. 만약 decay가 진행되는 도중에 최초 attack이 공간에서 반사되서 다시 측정마이크로 돌아와버리면...? 결과적으로 FR이 똑같이 나오게끔 변환기 전단에 EQ를 걸었다고 하더라도 임펄스 응답이 크게 틀어져버립니다. 잔향의 유무 혹은 특정한 CSD패턴이 음질이 좋고 나쁨을 말해준다는게 아니라, 잔향 패턴의 차이로 인해서 FR이 음질을 완전히 반영한다는 가정 자체가 성립이 안 된다는 얘깁니다.
무향실(FF)에 놓인 두 스피커의 FR이 모든 축상에서 같다면 두 스피커는 사실상 똑같은 변환기입니다. GD가 아마도 거의 똑같을 거고, 그러면 IR도 똑같을 겁니다. 여기에 이의는 없습니다. 일부 축상에서만 똑같다고 하더라도, "그 축상 응답만 활용할거다"라는 (비현실적인) 조건을 붙인다면 사실상 똑같은 변환기로 취급할 수 있습니다.
그러나 서로 다른 공간에 놓인 서로 다른 스피커의 FR이 똑같다면 그건 우연에 불과합니다.
무향실에서 플랫한 스피커를 잔향실에 가져다 놓고 EQ로 플랫하게 맞춰도 소리가 다릅니다.
잔향실에서 주파수 응답이 울룩불룩한 스피커를 무향실에 가져다 놓고 EQ로 똑같이 울룩불룩한 FR을 모의해도 소리가 다릅니다.
헤드폰 또는 이어폰의 진동판을 레이저로 찍어서 FR이 같다면 똑같은 유닛입니다. GD가 아마도 거의 똑같을 거고, 그러면 IR도 똑같을 겁니다.
그런데 헤드폰/이어폰은 사람의 머리와 물리적으로 결합되면서 소리가 방사되는 공간을 같이 제공합니다.
"서로 다른 헤드폰/이어폰"은 "서로 다른 변환기 & 서로 다른 공간"이 결합된 패키지입니다.
"서로 다른 헤드폰/이어폰"의 FR이 똑같다면 그건 우연에 불과합니다.
물론 공간의 유사성이 스피커 환경에 비해서 큰 편이므로, FR로 모든걸 알 수 있는 확률이 좀 더 높기는 합니다.
::요약::
"FR + GD ⇄ IR"이 모든걸 말해준다는 "완결성"은 수학적으로 완전한 이상적인 LTI 시스템에서만 보장되며, 현실의 전기-음향 변환기는 선형적으로 동작하는 범위가 제한되어 있기에 완전한 LTI 시스템이 아닙니다.
현실의 불완전한 LTI 시스템이 선형적으로 동작하는 범위를 정의하지 않으면, 두 변환기의 "FR + GD ⇄ IR"이 일치한다고 하더라도, 그로부터 나오는 변환결과가 서로 얼마나 일치하게 될지는 알 수 없습니다.
FR이 똑같은 두 개의 완전한 LTI 시스템을 가정하더라도, IR이 다르다면 전혀 다른 소리가 나옵니다. LTI 시스템에 대해서 모든 정보를 알려주는 것은 FR이 아닌 IR(즉, FR + GD)이기 때문입니다.
참고문헌
Douglas, B. (2019). The Fundamentals of Control Theory.
* 디씨스피커갤 글에 링크된 바로 그 PDF입니다
https://gall.dcinside.com/mgallery/board/view/?id=speakers&no=51768